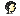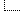|
>Без всякого сомнения, здесь записано слово с альфой и
>лямбдой,
Т.е. написано всё таки Гавриил, а не Гавриня или как Вы там умудрились прочесть это слово. Т.е. Вы совершили сознательный подлог, утверждая, что имена фигур русские(что на русском значит гавриня??????) а не библейские имена архангелов.
> Но проблема, не
>так записан текст «Ватиканского кодекса»
>http://ihtys.narod.ru/index.html
> нет там ни альфы ни лямбды.
Опять более чем странное заявление.
На первой же странице текста, первое же слово, содержащее лямбду, по счастью содержит и альфу, и, о чудо, обе эти буквы идут подряд, что даёт возможность оценить "проблему".

Мда, разница в написании едва уловимая, но она есть. Вот у меня наследственный "медицинский" почерк, у меня различить друг от друга большую часть букв вообще не возможно, даже мне самому. По сравнению с моими закорючками, это эталон каллиграфической чёткости, посему различить углы наклона в написании и положения вершин букв, для меня не составило труда.
Вот, кстати, обсуждаемый нами стих:

Видите, из-за другого разбиения по строчкам сочетание ААЛ в предпоследней строчке на мозаике превратилось в сочетание ААЛЛ в кодексе. Но оно таки отличается от слова АЛЛА часто встречающегося в тексте:

Да с устатку, по неопытности, или подгоняя под нужный результат, эти сочетания символов можно случайно или намеренно перепутать. Но Это не значит что в оригинале нет ни альф ни лямбд.
>По- этому, любой человек сильно
>не заморачиваясь, но задавшийсь целью получить перевод
>проделает ваши шаги и получит ваш же результат:
Хотите или не хотите, но объективная реальность такова, что таки да, получат результат. А вот, можно ли пользуясь вашими с Dimm-ом методиками получить стабильный результат, это, пока, всё ещё под очень большим вопросом.
Если мы возьмём текст из кодекса и прочтём на основе его словаря другой текст на греческом, то с высокой степенью вероятности получим новый осмысленный текст связанный с его контекстом и ещё с огромной массой текстов. Можно ли получить подобный результат Вашим методом?
>Зачем читать Морозова, ФиН и других исследователей задающих не
>удобные вопросы?
Затем, что они-то читают тексты как они есть, и анализируют их содержание, а не выдумывают новые правила чтения текстов и не генерят на основе этих правил новое содержание. Иначе нам придётся брать тексты и наново их перечитывать, а их прочтение фтопку. Так что, мне лично, легче почитать Морозова с ФиН, или даже традика кокого, чем заморачиваться с "новым прочтением".
>Сиди себе в поле «учебника» и не дёргайся.
В "учебниках", как ни крути, собрана и доступна нам масса информации, при чём, если она там даже искажена, то и эти искажения сами по себе несут информацию.
Несёт ли информацию ваше прочтение, вопрос всё ещё открыт.
>Следующий шаг – моё предположение, что при разбивки на слова
>нужно учитывать, что слова участвующие в построении фразы
>буквально разбросаны по иноязычным словарям.
Здесь Вы попадаете в элементарную ловушку. Количество звукосочетаний, особенно удобных для произношения, сравнительно невелико, посему получается огромное количество элементарных созвучий в разных языках. Вот знал я вьетнамца по фамилии Хyй, вот так прям и писалось в его русских документах. Не думаю, однако, что в его родном языке имелось в виду то же, что и на наших заборах. "Фильтрация" такой случайной похожести слов в разных языках, дело очень тонкое и трудное. Доказательство неслучайности схожетси, т.е. обратная задача фильтрации, один из методов, но тоже очень не лёгкая задача. Поэтому просто брать слова, потому как они что-то там напоминают и использовать для такого вот субъективного перевода, дело не благодарное. Чисто статистически можно, конечно, и попасть пару раз "в яблочко", но чаще всего это будет "в молоко".
С другой стороны, существуют древние слова, по крайней мере, я придерживаюсь такой теории, которые входят в огромное число языков, в мало изменённом виде и с сохранением семантических связей. В таких случаях созвучия не случайны, а совсем даже наоборот. Это обилие древних связей порождает кучу кучную теорий о превосходстве какого-то языка над другим, обычно авторы таких теорий превозносят свой родной язык, так как только его и знают. Хотя наглядный опыт построения таких теорий на основе практически любого языка, со всей очевидностью доказывает несостоятельность таких попыток, а наоборот, лишь верность представления о том, что все эти языки имеют общий древний корень.
Для примера
>«Ватиканский кодекс», от Иоанна: ПРОСеТОNи – простонал. Здесь
>русский глагол- просить + заимствованное слово тон = просящим
>тоном – тихим стонущим голосом;
Вот не любите Вы "учебники", поэтому "тон" для Вас отдельно гуляет от "стона", хотя в любом "учебнике", даже у проклятущего Фасмера, связь этих слов через единую праоснову никоим образом не отрицается.
В результате так и не понял, чем Вам русское "стонать" не угодило?
|