2.ИСТОРИЯ КАК НАУКА
2.5.ПОИСК АВТОРСКОГО ИНВАРИАНТА РУССКИХ ЛИТЕРАТУРНЫХ ТЕКСТОВ
В.П. и Т.Г. Фоменко в 1974-1981 годах обнаружили авторский инвариант для русских литературных текстов. Под АВТОРСКИМ ИНВАРИАНТОМ понимается количественная характеристика текстов, которая, с одной стороны, практически постоянна для произведений одного автора, а, с другой стороны, принимает существенно разные значения для произведений разных групп авторов. Авторский инвариант должен СЛАБО КОНТРОЛИРОВАТЬСЯ автором на сознательном уровне. Величина шага для книг большого объема равнялся 60 страницам стандартного книжного текста. Величина выборки варьировалась и достигала вплоть до 16000 слов. В качестве гипотез инварианта исследовались ДЛИНА ПРЕДЛОЖЕНИЙ, ДЛИНА СЛОВ, ОБЩАЯ ЧАСТОТА УПОТРЕБЛЕНИЯ СЛУЖЕБНЫХ СЛОВ, ЧАСТОТА УПОТРЕБЛЕНИЯ СУЩЕСТВИТЕЛЬНЫХ, ЧАСТОТА УПОТРЕБЛЕНИЯ ГЛАГОЛОВ, ЧАСТОТА УПОТРЕБЛЕНИЯ ПРИЛАГАТЕЛЬНЫХ, ЧАСТОТА УПОТРЕБЛЕНИЯ ПРЕДЛОГА "В", ЧАСТОТА УПОТРЕБЛЕНИЯ ЧАСТИЦЫ "НЕ", КОЛИЧЕСТВО СЛУЖЕБНЫХ СЛОВ В ПРЕДЛОЖЕНИИ. Авторским инвариантом является из 9 исследованных гипотез только ОБЩАЯ ЧАСТОТА УПОТРЕБЛЕНИЯ СЛУЖЕБНЫХ СЛОВ - ПРЕДЛОГОВ, СОЮЗОВ, ЧАСТИЦ, то есть процентное содержание служебных слов в каждой выборке. Единственное исключение имеет веские причины, которые лишь подтверждают значимость полученного инварианта. Для достаточно уверенных выводов по авторству нужны тексты большого объема. Обнаруженный авторский инвариант практически не зависит от временной эпохи: в указанном списке авторов представлены десятки писателей трех веков - от XVIII до XX.
Информация о поиске авторского инварианта основывается на материалах исследования, выполненного Валентиной Поликарповной Фоменко и Тимофеем Григорьевичем Фоменко в 1974-1981 годах. Главным результатом работы является обнаружение авторского инварианта для русских литературных текстов. Он позволяет различать некоторых авторов и оказывается полезным при решении проблем, связанных с плагиатом. Этот результат был получен на основе общей идеи статистического анализа функций объема для текстов. Материал показывает, как могут эмпирико-статистические методы использоваться при решении не только хронологических, но и других смежных проблем, например, при установлении авторства письменного документа. Такие проблемы часто возникают в литературе, истории, лингвистике.
Действительно ли диалоги Платона написаны одним человеком? Правда ли, что пьесы Шекспира - творения одного гения? Или же они написаны разными людьми? Кто в действительности скрывается под именем "Шекспир"? Специальный интерес приобретает эта проблема, когда возникает подозрение в плагиате. Особое звучание задачи такого сорта приобретают при исследовании ДРЕВНИХ текстов, данные об авторах которых утрачены или сомнительны.
Проблеме обнаружения авторских инвариантов посвящена значительная научная литература. Так, например, структура языка различных авторов изучалась с помощью отдельных распорядительных слов, в частности, предлога "в", частицы "не", или при помощи длины предложений и слов. Однако, как показали исследования, использование лингвистических спектров ОТДЕЛЬНЫХ распорядительных слов не позволяет обнаружить устойчивые инварианты. На это указал еще в 1916 году академик А.А.Марков, отметивший что при больших объемах выборок результаты такого типа должны "колебаться около среднего числа, подчиняясь общим законам языка", что естественно затрудняет различение авторов.
Полезный подход продемонстрирован в ряде работ В.Фукса, где каждому автору сопоставляются такие его характеристики, как среднее количество слогов и среднее количество слов в предложении. Этот прием позволяет изобразить текст (автора) точкой на плоскости в случае использования двух параметров, или же точкой в многомерном пространстве (если число параметров возрастает).
Следует отметить общую характерную особенность этих и многих других исследований. Обычно изучаются индивидуальные количественные параметры текстов и путем их сравнения. Главным вопросом здесь является - какие различия следует считать значимыми, а какие - нет. Тут открывается простор для субъективизма. И здесь коренятся главные трудности применения статистических методов к задачам такого сорта.
И все же проблема в значительной мере разрешима, если найти корректный авторский инвариант. Под АВТОРСКИМ ИНВАРИАНТОМ понимается количественная характеристика литературных текстов (некий параметр), которая, с одной стороны, однозначно характеризует своим поведением произведения одного автора или небольшого числа "близких авторов", а, с другой стороны, принимает существенно разные значения для произведений разных групп авторов. Желательно, чтобы число разных групп было достаточно велико, и чтобы каждая группа объединяла незначительное количество похожих, то есть близких по стилю авторов.
Однако многообразие грамматических структур, участвующих в формировании литературных текстов, сильно затрудняет поиски таких инвариантов. Уже простые вычислительные эксперименты показывают, что обнаружение числовых характеристик, различающих разных авторов, - сложная задача. Дело в том, что когда человек пишет книгу, то существенную роль играют не только подсознательные, но и сознательные факторы. Например, частота употребления автором РЕДКИХ И ИНОСТРАННЫХ СЛОВ может, конечно, служить неким показателем его стиля, эрудиции. Однако этот показатель ЛЕГКО КОНТРОЛИРУЕТСЯ автором на СОЗНАТЕЛЬНОМ уровне, поскольку редкие и иностранные слова вставляются в текст нечасто и каждый раз автор специально отмечает про себя: "здесь я вставляю иностранное или редкое слово". В результате, как неопровержимо свидетельствуют конкретные подсчеты, использовать эту числовую характеристику в качестве авторского инварианта НЕЛЬЗЯ. Она контролируется автором, "скачет" и писатель может легко менять ее от произведения к произведению.
Сформулируем теперь точнее - какими свойствами должен обладать авторский инвариант. Искомая числовая характеристика должна удовлетворять следующим естественным требованиям.
1) Она должна быть достаточно "массовой", интегральной, чтобы СЛАБО КОНТРОЛИРОВАТЬСЯ автором на сознательном уровне. Другими словами, она должна быть его "бессознательным параметром", коренящимся настолько глубоко, что автор даже не задумывается о нем. А если бы даже задумался, то не смог бы долго его контролировать и в результате довольно быстро вернулся бы в прежнее устойчивое и ТИПИЧНОЕ для него состояние.
2) Искомый параметр должен сохранять постоянное значение для произведений данного автора. То есть, иметь небольшое отклонение от среднего значения (слабо колебаться) на протяжении всех его книг. Именно это свойство и позволяет говорить, что данный параметр является ИНВАРИАНТОМ.
3) Наконец, параметр должен уверенно различать между собой разные группы писателей. Другими словами, должно существовать достаточное число авторских групп, заметно отличающихся друг от друга значениями инварианта.
Третье условие важно. Ведь может случиться так, что некий параметр окажется слабо колеблющимся вдоль произведений каждого отдельного писателя, однако в то же время принимает ОДНО И ТО ЖЕ ЗНАЧЕНИЕ, будучи вычислен для РАЗНЫХ авторов. Другими словами, он не позволяет различать писателей. ТОЛЬКО СОЧЕТАНИЕ ВСЕХ ТРЕХ ПЕРЕЧИСЛЕННЫХ УСЛОВИЙ ПОЗВОЛЯЕТ ГОВОРИТЬ, ЧТО ОБНАРУЖЕН АВТОРСКИЙ ИНВАРИАНТ.
Пусть в нашем распоряжении оказалось какое-то количество произведений одного писателя. Для удобства упорядочим их хронологически (то есть в порядке написания) и для краткости назовем получившуюся совокупность - ТЕКСТОМ ДАННОГО АВТОРА. Таким образом, текст автора (в нашем определении) может состоять из нескольких различных произведений - романов, повестей, рассказов и т.п.
Выделим теперь из этого текста отдельные фрагменты - выборки одинакового объема, то есть состоящие из одного и того же (фиксированного заранее) количества слов. Это количество слов естественно назвать ОБЪЕМОМ ВЫБОРКИ. Эти равновеликие (равные по объему) выборки мы будем выделять из текста ЧЕРЕЗ РАВНЫЕ ИНТЕРВАЛЫ, то есть таким образом, чтобы каждые две соседние выборки были отделены друг от друга примерно одним и тем же количеством слов. Это "расстояние", интервал между соседними выборками мы назовем ШАГОМ, рис.2.43 . Объем выборок и их шаг можно варьировать в зависимости от поставленных задач.
. Объем выборок и их шаг можно варьировать в зависимости от поставленных задач.
Итак, последовательно двигаясь по тексту одного автора, через каждые, например, 10 страниц стандартного книжного текста будем делать выборки одного и того же объема, например, в 2000 слов. Чем длиннее исследуемый текст, тем больше выборок мы сможем сделать. Для коротких произведений число выборок будет невелико, что усложняет анализ, делает результаты неустойчивыми.
Пусть теперь мы избрали какой-либо лингвистический параметр, например частоту употребления писателем предлога "в". Можно изучить эволюцию этого параметра вдоль всего текста, состоящего, быть может, из нескольких отдельных произведений, выстроенных нами в ряд. Для этого сделаем последовательные выборки и подсчитаем для каждой из них значение интересующего нас лингвистического параметра. В результате для каждой выборки (порции) получим свое число. От выборки к выборке оно будет, вообще говоря, меняться. Построим график, отложив по горизонтали целые числа 1,2,3,..., являющиеся номерами последовательных выборок, а по вертикали - значения изучаемой нами лингвистической характеристики.
В результате, эволюция данного параметра вдоль всего исследуемого текста изобразится некоторой ломаной линией. Следовательно, мы представили каждого писателя не точкой на плоскости или в пространстве, как это часто делалось в других работах, а графиком - ломаной линией. Она наглядно показывает поведение исследуемого параметра вдоль произведений данного автора. Оказывается, такие графики очень удобны при поиске авторских инвариантов. В самом деле, теперь задача может быть переформулирована так.
Требуется найти такой лингвистический параметр и такой оптимальный объем выборок, чтобы соответствующие им графики изображались бы для каждого автора ПРАКТИЧЕСКИ ГОРИЗОНТАЛЬНЫМИ ЛИНИЯМИ - "ПРЯМЫМИ", то есть слабо колеблющимися ломаными. Другими словами, это будет означать, что числовые значения найденного инварианта мало отклоняются от своего среднего значения вдоль произведений каждого отдельного автора. Это явление - сглаживание ломаной кривой и ее стремление к горизонтальной прямой - назовем СТАБИЛИЗАЦИЕЙ лингвистического параметра.
Однако одного факта стабилизации еще недостаточно, чтобы можно было объявить данный параметр - авторским инвариантом. Совершенно необходимо, чтобы стабилизировавшиеся графики (то есть практически горизонтальные прямые), отвечающие разным группам писателей, ЗНАЧИТЕЛЬНО ОТЛИЧАЛИСЬ бы друг от друга по высоте. То есть, они должны лежать на существенно разных уровнях. Напомним еще раз, что иногда "горизонтальные прямые", отвечающие разным авторам, могут оказаться близкими, лежащими на одном уровне. В этих случаях значения авторских инвариантов близки. Мы отнесем к одной группе писателей с близкими значениями параметров. Чтобы авторский инвариант был действительно эффективен, он должен разделить совокупность всех писателей на несколько групп с существенно разными значениями инварианта.
Если значения авторского инварианта для двух сравниваемых текстов оказываются близкими, отсюда нельзя делать заключение об их принадлежности одному писателю. Ясно, что само существование таких замечательных лингвистических инвариантов ниоткуда не следует. Для их выявления требуется обширный вычислительный эксперимент. И такой эксперимент был проведен на протяжении нескольких лет.
Перейдем к изложению результатов.
Для обнаружения "бессознательного параметра" – авторского инварианта, слабо или вообще не контролируемого писателями, изучили следующие количественные характеристики текстов:
1) ДЛИНА ПРЕДЛОЖЕНИЙ, то есть среднее число слов в предложении (подсчитанное для каждой выборки).
2) ДЛИНА СЛОВ, то есть среднее количество слогов в слове, подсчитанное для каждой выборки.
3) ОБЩАЯ ЧАСТОТА УПОТРЕБЛЕНИЯ СЛУЖЕБНЫХ СЛОВ - ПРЕДЛОГОВ, СОЮЗОВ, ЧАСТИЦ, то есть процентное содержание служебных слов в каждой выборке.
4) ЧАСТОТА УПОТРЕБЛЕНИЯ СУЩЕСТВИТЕЛЬНЫХ, то есть их процентное содержание в каждой выборке.
5) ЧАСТОТА УПОТРЕБЛЕНИЯ ГЛАГОЛОВ, то есть их процентное содержание в каждой выборке.
6) ЧАСТОТА УПОТРЕБЛЕНИЯ ПРИЛАГАТЕЛЬНЫХ (в процентах).
7) ЧАСТОТА УПОТРЕБЛЕНИЯ ПРЕДЛОГА "В" (в процентах).
8) ЧАСТОТА УПОТРЕБЛЕНИЯ ЧАСТИЦЫ "НЕ" (в процентах).
9) КОЛИЧЕСТВО СЛУЖЕБНЫХ СЛОВ В ПРЕДЛОЖЕНИИ, то есть среднее число союзов, предлогов и частиц в предложении.
Некоторые из перечисленных параметров рассматривались ранее. Однако предложенный параметр 3 - частота всех служебных слов – является НОВЫМ. Указанные параметры существенно различны по своему характеру. Параметр 3 особо выделяется своей интегральностью, "массовостью", так как здесь подсчитывается суммарный процент ВСЕХ СЛУЖЕБНЫХ СЛОВ, которых очень много! Большое число служебных слов, используемых в русском языке, делает этот параметр невероятно трудно контролируемым на сознательном уровне. Писатель может легко следить, например, за длиной своих предложений. Однако трудно представить себе автора, который при написании книги смог бы уследить за процентом своих служебных слов!
Параметры 7 (частота предлога "в") и 8 (частота частицы "не") описывают распределение отдельных служебных слов и заметно менее "массовым", чем суммарный параметр 3. Параметры 7 и 8 включены в список, чтобы выяснить - стабилизируются ли они и могут ли служить в качестве авторских инвариантов (ответ оказался отрицательным).
Параметр 9 - количество служебных слов в предложении – хотя и носит интегральный характер, однако существенно зависит от длины предложений и следовательно от их числа в выборке. А эта последняя величина, как показали подсчеты, весьма неустойчива и может колебаться в заметных пределах, не стабилизируясь.
Величина шага, то есть интервал между соседними выборками, для книг большого объема равнялся 60 страницам стандартного книжного текста. Величина же выборки варьировалась. Размер начальной порции, в отличие от 1000 слов, ранее принимавшийся многими авторами, был принят равным 2000 слов. Затем объем выборок последовательно увеличивался, а именно - 4000, 8000, 16000 слов.
Проведенный эксперимент показал, что дальнейшее увеличение объема выборок не обязательно, так как искомый АВТОРСКИЙ ИНВАРИАНТ был обнаружен уже при величине выборки в 16000 слов. При исследовании текстов небольшого объема величина шага уменьшалась, и выборки производились чаще. Впрочем, как показал эксперимент, величина шага (в отличие от объема выборки) мало сказывается на окончательных результатах.
В качестве критерия стабилизации был взят следующий принцип. Объем выборки увеличивался до тех пор, пока не обнаруживался параметр, для которого средняя величина его отклонений от средних значений вдоль произведений всех исследуемых писателей оказывалась существенно меньше амплитуды колебаний параметра между текстами разных авторов.
Другими словами, для каждого автора вычислялось отклонение параметра от среднего значения, а затем эти отклонения усреднялись по всем авторам. Разыскивался параметр, для которого это последнее число существенно меньше разницы между максимальным и минимальным значениями параметра по всем исследуемым писателям.
Для анализа был выбран список из 23 писателей. Для каждого писателя были обработаны все его основные книги. Оказалось, что полученные результаты практически не зависят от объема произведений при условии, что объемы достаточно велики. Приведем список обработанных литературных произведений.
ПИСАТЕЛИ XVIII ВЕКА:
1) ЧУЛКОВ М.Д. (1743-1792) - роман "Пригожая повариха" (написан в 1770 г.), М., 1971.
2) НОВИКОВ Н.И. (1744-1818) - сатирический журнал "Живописец" (издан в 1772-1773 гг.), М., 1971.
3) ФОНВИЗИН Д.И. (1745-1792) - "Записки первого путешествия" (написаны в 1777-1778 гг.), повесть "Повествование глухого и немого" (издана в 1783 г.), повесть "Калисфен" (издана в 1786 г.), сочинение в письмах "Друг честных людей или стародум" (издано в 1830 г.), мемуары "Чистосердечное признание в делах моих и помышлениях" (изданы в 1830 г.), М., 1971.
4) РАДИЩЕВ А.Н. (1749-1802) - "Путешествие из Петербурга в Москву" (издано в 1790 г.), М., 1971.
5) КАРАМЗИН Н.М. (1766-1826) - "История Государства Российского" (написана в 1816-1826 гг.), повесть "Бедная Лиза" (издана в 1792 г.), повесть "Остров Бернгольм" (издана в 1794 г.), повесть "Марфа Посадская" (издана в 1803 г.), М., 1971.
6) КРЫЛОВ И.А. (1769-1844) - повесть "Каиб" (издана в 1792 г.), "Похвальная речь" (издана в 1792 г.), М., 1971.
ПИСАТЕЛИ XIX ВЕКА:
7) ГОГОЛЬ Н.В. (1809-1852) - повести: "Вечера на хуторе близ Диканьки", "Сорочинская ярмарка", "Вечер накануне Ивана Купала", "Майская ночь или утопленница", "Пропавшая грамота", "Ночь перед Рождеством", "Страшная месть", "Иван Иванович и его тетушка", "Заколдованное место" (изданы в 1831-1832 гг.), повести: "Миргород", "Старосветские помещики", "Тарас Бульба", "Вий", "Повесть о том, как поссорились Иван Иванович с Иваном Никифоровичем" (изданы в 1835 г.), "Повести" (Петербургские): "Невский проспект", "Нос", "Портной", "Шинель", "Коляска", "Записки сумасшедшего", "Рим" (изданы в 1833-1842 гг.), поэма "Мертвые души" (издана в 1840 г.), М., 1959, 1971.
8) ГЕРЦЕН А.И. (1812-1870) - мемуары "Былое и думы" (изданы в 1852-1868 гг.), М., 1969.
9) ГОНЧАРОВ И.А. (1812-1891) - роман "Обыкновенная история" (издан в 1847 г.), роман "Обломов" (издан в 1859 г.), роман "Обрыв" (издан в 1869 г.), М., 1959.
10) ТУРГЕНЕВ И.С. (1818-1883) - "Записки охотника" (написаны в 1855-1856 гг.), роман "Рудин" (написан в 1855-1856 гг.), роман "Дворянское гнездо" (написан в 1859 г.), роман "Накануне" (написан в 1860 г.), роман "Отцы и дети" (написан в 1862 г.), М., 1961.
11) МЕЛЬНИКОВ-ПЕЧЕРСКИЙ П.И. (1818-1883) - "Красильниковы" (дорожные записки, 1852 г.), рассказ "Дедушка Поликарп" (написан в 1857 г.), рассказ "Поярков" (написан в 1857 г.), рассказ "Старые годы" (написан в 1857 г.), роман "В лесах" (написан в 1871-1875 гг.), М., 1963.
12) ДОСТОЕВСКИЙ Ф.М. (1821-1881) - роман "Преступление и наказание" (написан в 1866 г.), роман "Братья Карамазовы" (написан в 1879-1880 гг.), М., 1970-1973.
13) САЛТЫКОВ-ЩЕДРИН М.Е. (1826-1889) - "История одного города" (написана в 1869-1870 гг.), роман "Господа Головлевы" (написан в 1875-1880 гг.), М., 1975.
14) ЛЕСКОВ Н.С. (1831-1895) - повесть "Леди Макбет Мценского уезда" (написана в 1864 г.), повесть "Воительница" (написана в 1866 г.), "Запечатленный ангел" (повесть написана в 1873 г.), повесть "Очарованный странник" (написана в 1873 г.), рассказ "Железная воля" (написан в 1876 г.), рассказ "Однодум" (написан в 1879 г.), рассказ "Несмертельный голован" (написан в 1880 г.), рассказ "Левша" (написан в 1881 г.), рассказ "Тупейный художник" (написан в 1883 г.), рассказ "Человек на часах" (написан в 1889 г.), рассказ "Зимний день" (написан в 1894 г.), М., 1973.
15) ТОЛСТОЙ Л.Н. (1828-1910) - повесть "Детство" (написана в 1852 г.), повесть "Отрочество" (написана в 1854 г.), повесть "Юность" (написана в 1856 г.), рассказ "Набег" (написан в 1852 г.), повесть "Утро помещика" (написана в 1856 г.), повесть "Казаки" (написана в 1863 г.), роман "Война и мир" (написан в 1863-1869 гг.), роман "Анна Каренина" (написан в 1873-1877 гг.), роман "Воскресение" (написан в 1899 г.), М., 1960-1964.
ПИСАТЕЛИ XX ВЕКА:
16) ГОРЬКИЙ А.М. (1868-1936) - рассказ "Макар Чудра" (написан в 1892 г.), рассказ "Дед Архип и Ленька" (написан в 1894 г.), рассказ "Старуха Изергиль" (написан в 1894-1895 гг.), рассказ "Ошибка" (написан в 1895 г.), рассказ "Однажды ночью" (написан в 1895 г.), рассказ "Озорник" (написан в 1896 г.), рассказ "Товарищи" (написан в 1897 г.), рассказ "Супруги Орловы" (написан в 1897 г.), рассказ "Бывшие люди" (написан в 1897 г.), рассказ "Мальва" (написан в 1897 г.), рассказ "Скуки ради" (написан в 1897 г.), рассказ "Варенька Олесова" (написан в 1898 г.), рассказ "Дружки" (написан в 1898 г.), рассказ "Читатель" (написан в 1898 г.), М., 1939. Далее: повесть "Детство" (написана в 1912-1913 гг.), повесть "В людях" (написана в 1914-1915 гг.), повесть "Мои университеты" (написана в 1923 г.), повесть "Дело Артамоновых" (написана в 1925 г.), М., 1967.
17) БУНИН И.А. (1870-1953) - рассказ "Антоновские яблоки" (написан в 1900 г.), повесть "Деревня" (написана в 1909-1910 гг.), повесть "Суходол" (написана в 1911 г.), рассказ "Захар Воробьев" (написан в 1911-1912 гг.), рассказ "Братья" (написан в 1916 г.), рассказ "Господин из Сан-Франциско" (написан в 1915 г.), рассказ "Божье дерево" (написан в 1913 г.), рассказ "Натали" (написан в 1941 г.), рассказ "Чистый понедельник" (написан в 1944 г.), М., 1973.
18) НОВИКОВ-ПРИБОЙ А.С. (1877-1944) - рассказ "По-темному" (написан в 1911 г.), рассказ "Бойня" (написан в 1906 г.), рассказ "Пошутили" (написан в 1913 г.), рассказ "Порченный" (написан в 1912 г.), повесть "Море зовет" (написана в 1919 г.), роман "Капитан первого ранга" (написан в 1936-1944 гг.), роман "Цусима" (написан в 1905-1941 гг.), М., 1963.
19) ФЕДИН К.А. (1892-1977) - роман "Города и годы" (написан в 1924 г.), роман "Братья" (написан в 1928 г.), М., 1974.
20) ЛЕОНОВ Л.М. (род. 1899) - роман "Русский лес" (написан в 1953 г.), М., 1974.
21) ШИШКОВ В.Я. (1873-1945) - повесть "Тайга" (написана в 1916 г.), повесть "Пейнус-озеро" (написана в 1931 г.), роман "Угрюм-река" (написан в 1918-1932 гг.), М., 1960.
22) ФАДЕЕВ А.А. (1901-1956) - роман "Разгром" (написан в 1926 г.), роман "Молодая гвардия" (написан в 1945 г.).
23) ШОЛОХОВ М.А. (1905-1984) - собрание сочинений в 8 томах, М., 1962: ранние рассказы - том 1, роман "Тихий Дон" - тома 2-5, роман "Поднятая целина" - тома 6,7, рассказы - том 8.
Для каждого из этих писателей были полностью обработаны все указанные в списке сочинения. А именно, вдоль всех этих многотомных текстов были просчитаны значения девяти перечисленных лингвистических параметров. В результате построили частотные графики для выборок размером в 2000, 4000, 8000, 16000 слов. Вся эта огромная работа была выполнена "вручную", поскольку не нашлось компьютерных версий всех этих книг.
Принцип построения частотных графиков был таков. По горизонтали откладывались номера последовательных выборок, а по вертикали - численные значения лингвистических параметров. В результате каждому писателю отвечает некоторая ломаная кривая. Колебания параметров, их отклонения от среднего значения, подсчитывались по формуле
d = (H.макс - H.мин) / H.сред,
где H.макс, H.мин, H.сред - максимальное, минимальное и среднее значения соответственно.
Оказалось, что все перечисленные параметры за исключением параметра 3 при росте объема выборки либо не стабилизируются вообще, либо разброс их значений для одного автора сравним с максимальной разностью значений для разных авторов. Другими словами, в этом последнем случае "все авторы склеиваются", их невозможно численно отделить друг от друга. Ясно, что такие параметры не могут служить для различения хотя бы некоторых групп авторов.
Типичным примером первой ситуации (отсутствие стабилизации с ростом объема выборки) является эволюция параметра 1 – количества слов в предложении, рис.2.44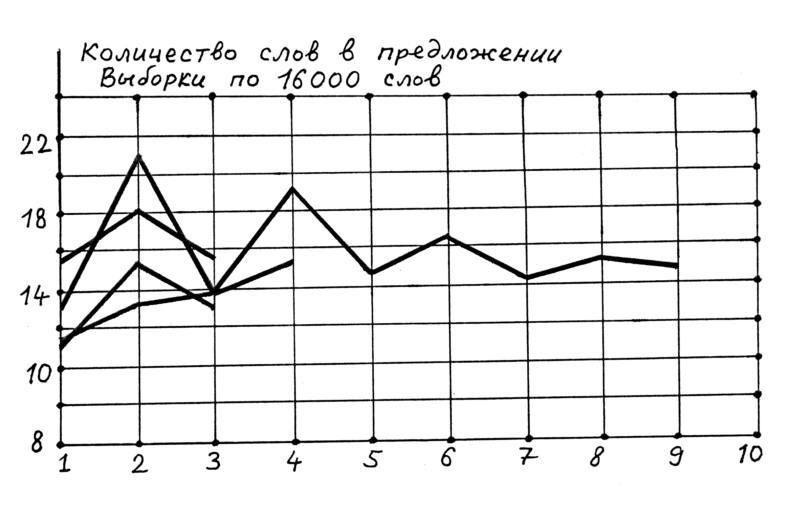 . Отчетливо видно, что даже при объеме выборок в 16000 слов кривые хаотичны, сильно перемешаны и размах колебаний слишком велик.
. Отчетливо видно, что даже при объеме выборок в 16000 слов кривые хаотичны, сильно перемешаны и размах колебаний слишком велик.
Типичным примером второй ситуации ("слипание всех писателей") является поведение параметра 2 - количества слогов в слове, рис.2.45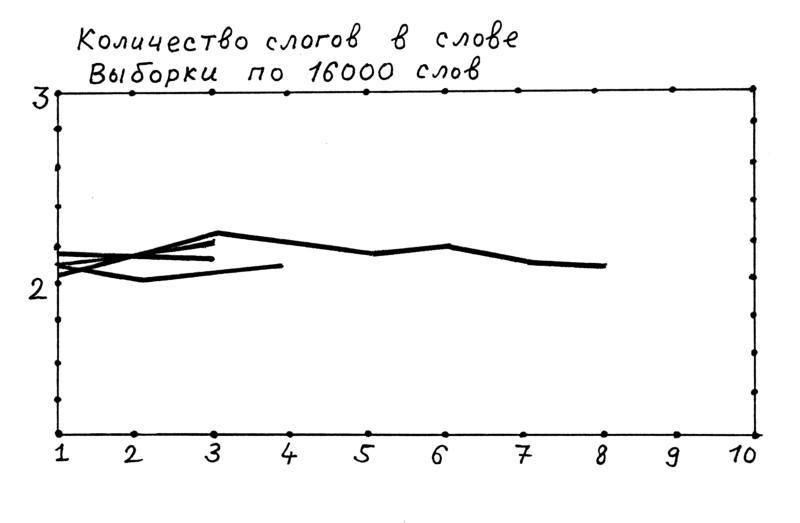 . Хотя при объеме выборок в 16000 слов кривые начинаются выпрямляться, стабилизироваться, однако все траектории практически сливаются друг с другом, слипаются, что делает невозможным различение авторов.
. Хотя при объеме выборок в 16000 слов кривые начинаются выпрямляться, стабилизироваться, однако все траектории практически сливаются друг с другом, слипаются, что делает невозможным различение авторов.
Аналогичная картина наблюдается и для параметров 4,5,6,7,8,9. Например, кривые параметра 9 не стабилизируются и перемешиваются. Поведение параметра 8 похоже на поведение параметра 2 - хотя при большом объеме выборок кривые выравниваются, однако они становятся очень близкими друг к другу, стремятся к одному и тому же значению, определяемому, следовательно, общими законами русского языка, а не индивидуальными особенностями писателя.
Таким образом, представляется сомнительным использование параметров 1,2,4,5,6,7,8,9 для различения авторов.
Замечательным исключением является параметр 3 – частота употребления всех служебных слов - ПРЕДЛОГОВ, СОЮЗОВ И ЧАСТИЦ. Эволюция этого параметра в зависимости от роста объема выборки показана на рис.2.46 , рис.2.47
, рис.2.47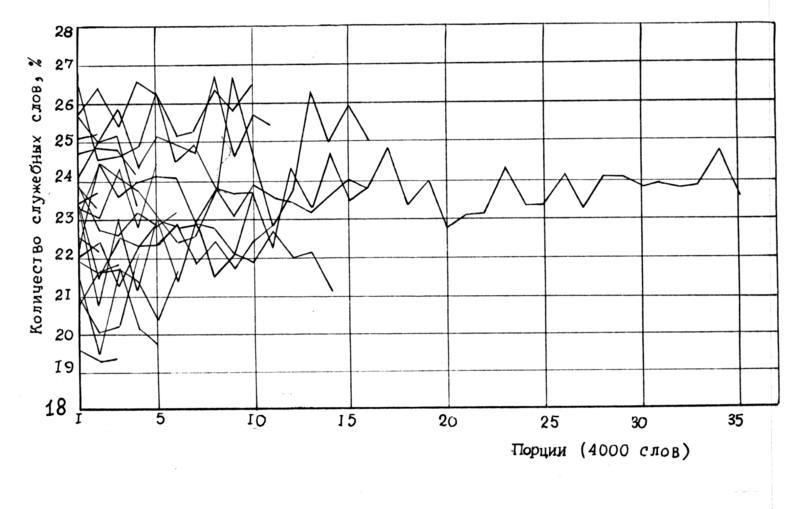 , рис.2.48
, рис.2.48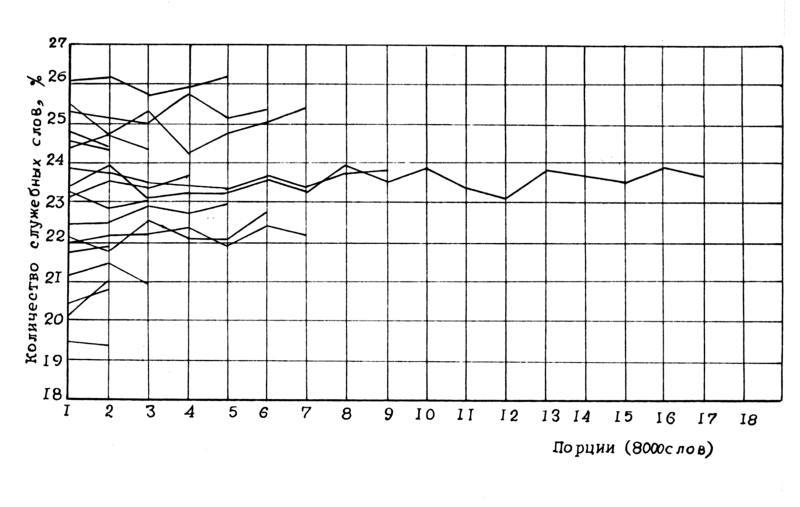 , рис.2.49
, рис.2.49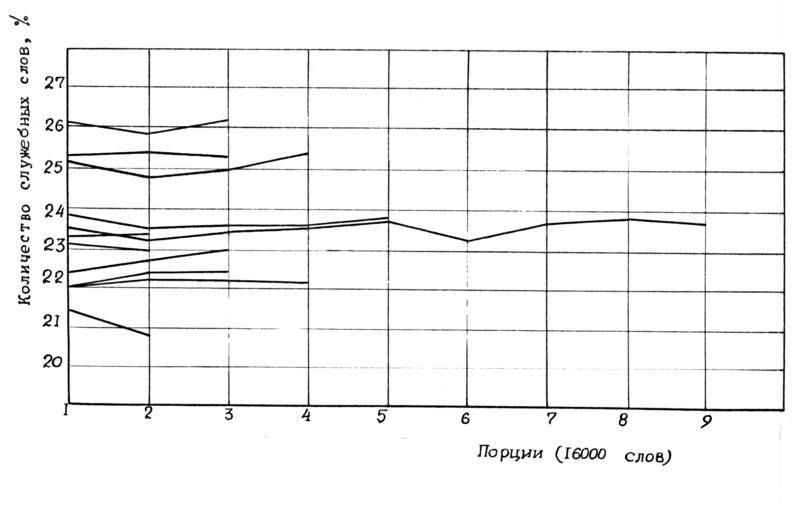 .
.
При этом в список служебных слов внесены следующие слова:
ПРЕДЛОГИ - в, на, с, за, к, по, из, у, от, для, во, без, до, о, через, со, при, про, об, ко, над, из-за, из-под, под.
СОЮЗЫ - и, что, но, а, да, хотя, когда, чтобы, если, тоже, или, то есть, зато, будто.
ЧАСТИЦЫ - не, как, же, даже, бы, ли, только, вот, то, ни, лишь, ведь, вон, то-есть, нибудь, уже, либо.
Итого - 55 служебных слов. (По мнению В.А.Никерова, статистически немалое количество служебных слов стало одной из основных причин успешности этого инварианта.) Хотя список не полон, он оказался вполне достаточным для различения авторов.
Из расчетов следуют важные выводы:
1) При величине выборок в 16000 слов процентное содержание служебных слов для каждого автора из списка (за исключением одного писателя, о котором речь пойдет ниже) оказалось приблизительно постоянным вдоль всех его произведений, то есть частотный график изображается практически горизонтальной прямой. Эта стабилизация происходит для всех 22 писателей (из 23 исследованных), рис.2.49. А единственное исключение, как будет показано ниже, имеет веские причины, которые лишь подтверждают значимость полученного инварианта.
2) Разность между максимальным и минимальным значениями параметра 3 (минимум и максимум взяты по всем исследованным писателям) значительно больше амплитуды его колебаний внутри произведений отдельных авторов. Амплитуда колебаний параметра 3 по разным писателям достаточно велика - от 19% до 27,5%. Отсюда следует, что параметр 3 хорошо различает многих авторов.
На этом основании назовем параметр 3 – АВТОРСКИМ ИНВАРИАНТОМ.
Он может служить для атрибуции неизвестных произведений и для обнаружения плагиата, хотя и с определенной осторожностью, поскольку были обнаружены писатели с очень близкими авторскими инвариантами, например, Фонвизин Д.И. и Толстой Л.Н. Кроме того, для достаточно уверенных выводов нужны тексты большого объема.
Главным выводом здесь является нетривиальное утверждение о существовании авторского инварианта русских литературных текстов. Было бы интересно продолжить эксперименты с целью обнаружения других авторских инвариантов.
Подчеркнем, что подобные выводы можно делать только после проведения обширного вычислительного эксперимента. Лишь после того, как будет экспериментально доказано, что тот или иной параметр действительно стабилизируется внутри произведений каждого писателя, можно считать, что мы обнаружили инвариант. При этом обработанный список авторов должен быть достаточно велик - по крайней мере несколько десятков. Строить же какие либо теории лишь на основе сравнения текстов одного или двух писателей едва ли корректно.
Интересно, что обнаруженный авторский инвариант практически не зависит от временной эпохи: в указанном списке авторов представлены писатели трех веков - от XVIII до XX.